
今天碰到一次因死锁导致更新操作的sql事务执行时间过长,特将排查过程记录如下:
首先该sql事务的where条件已经命中了主键索引,而且表也不大,故可以排除扫表过慢原因。通过 show processlist;发现也只有该sql事务在操作这个表,初看起来似乎也不像是死锁的原因:

但通过咨询yellbehuang后发现,判断sql事务是否死锁不能简单通过show processlist来判断,而是要通过查询innodb锁的相关表来确定,和innodb锁有关的主要有三个表,
innodb_trx ## 当前运行的所有事务
innodb_locks ## 当前出现的锁
innodb_lock_waits ## 锁等待的对应关系
上面表的各个字段的含义如下:
innodb_locks:
+————-+———————+——+—–+———+——-+
| Field | Type | Null | Key | Default | Extra |
+————-+———————+——+—–+———+——-+
| lock_id | varchar(81) | NO | | | |#锁ID
| lock_trx_id | varchar(18) | NO | | | |#拥有锁的事务ID
| lock_mode | varchar(32) | NO | | | |#锁模式
| lock_type | varchar(32) | NO | | | |#锁类型
| lock_table | varchar(1024) | NO | | | |#被锁的表
| lock_index | varchar(1024) | YES | | NULL | |#被锁的索引
| lock_space | bigint(21) unsigned | YES | | NULL | |#被锁的表空间号
| lock_page | bigint(21) unsigned | YES | | NULL | |#被锁的页号
| lock_rec | bigint(21) unsigned | YES | | NULL | |#被锁的记录号
| lock_data | varchar(8192) | YES | | NULL | |#被锁的数据
innodb_lock_waits:
+-------------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------------+-------------+------+-----+---------+-------+
| requesting_trx_id | varchar(18) | NO | | | |#请求锁的事务ID
| requested_lock_id | varchar(81) | NO | | | |#请求锁的锁ID
| blocking_trx_id | varchar(18) | NO | | | |#当前拥有锁的事务ID
| blocking_lock_id | varchar(81) | NO | | | |#当前拥有锁的锁ID
+-------------------+-------------+------+-----+---------+-------+
innodb_trx :
+—————————-+———————+——+—–+———————+——-+
| Field | Type | Null | Key | Extra |
+—————————-+———————+——+—–+———————+——-+
| trx_id | varchar(18) | NO | | |#事务ID
| trx_state | varchar(13) | NO | | |#事务状态:
| trx_started | datetime | NO | | |#事务开始时间;
| trx_requested_lock_id | varchar(81) | YES | | |#innodb_locks.lock_id
| trx_wait_started | datetime | YES | | |#事务开始等待的时间
| trx_weight | bigint(21) unsigned | NO | | |#
| trx_mysql_thread_id | bigint(21) unsigned | NO | | |#事务线程ID
| trx_query | varchar(1024) | YES | | |#具体SQL语句
| trx_operation_state | varchar(64) | YES | | |#事务当前操作状态
| trx_tables_in_use | bigint(21) unsigned | NO | | |#事务中有多少个表被使用
| trx_tables_locked | bigint(21) unsigned | NO | | |#事务拥有多少个锁
| trx_lock_structs | bigint(21) unsigned | NO | | |#
| trx_lock_memory_bytes | bigint(21) unsigned | NO | | |#事务锁住的内存大小(B)
| trx_rows_locked | bigint(21) unsigned | NO | | |#事务锁住的行数
| trx_rows_modified | bigint(21) unsigned | NO | | |#事务更改的行数
| trx_concurrency_tickets | bigint(21) unsigned | NO | | |#事务并发票数
| trx_isolation_level | varchar(16) | NO | | |#事务隔离级别
| trx_unique_checks | int(1) | NO | | |#是否唯一性检查
| trx_foreign_key_checks | int(1) | NO | | |#是否外键检查
| trx_last_foreign_key_error | varchar(256) | YES | | |#最后的外键错误
| trx_adaptive_hash_latched | int(1) | NO | | |#
| trx_adaptive_hash_timeout | bigint(21) unsigned | NO | | |#
可以通过select * from INNODB_LOCKS a inner join INNODB_TRX b on a.lock_trx_id=b.trx_id and trx_mysql_thread_id=线程id 来获取该sql的锁状态,线程id可以通过上面的show processlist来获得,执行结果如下:
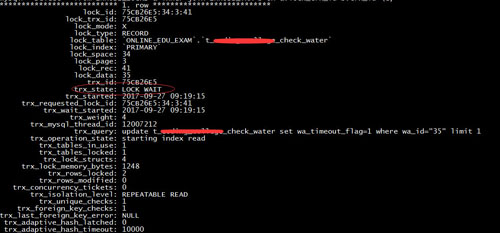
此时发现,该sql连接确实处于LOCK WAIT锁等待状态
通过select * from innodb_lock_waits where requesting_trx_id=75CB26E5(即上面查询得到的lock_trx_id)可以得到当前拥有锁的事务ID 75CB26AE。
![]()
再通过select * from innodb_trx where lock_trx_id=75CB26AE获取sql语句与线程id
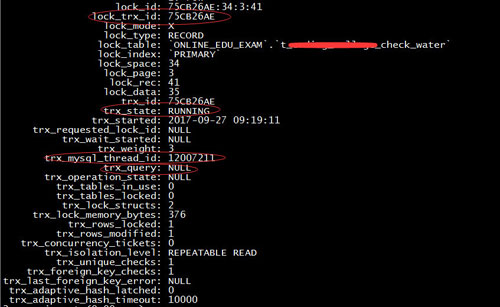
从上面的结果中看出,该事务处于running状态,但sql却为null,该线程id即对于上面show processlist的206机器的30764端口的连接,该连接处于sleep状态。为什么sql为null却依然占有锁?在查询相关资料和咨询jameszhou后,知道了这个实际和innodb 引擎的写机制有关,innodb执行写事务操作时,实际是先取得索引中该行的行锁(即使该表上没有任何索引,那么innodb会在后台创建一个隐藏的聚集主键索引),再在缓存里写入,最后事务commit后正式写入DB中并释放锁。之所以sql为null,是因为该连接已经把sql update操作执行写入缓存中了,但是由于代码bug没有最后commit,导致一直占用着行锁,后续新的连接想写这一行数据却因为一直取不到行锁而处于长时间的等待状态。
那为什么innodb需要两次写?下面是我查询相关资料得出来的结论:
因为innodb中的日志是逻辑的,所谓逻辑就是比如当插入一条记录时,它可能会导致在某一个页面(这条记录最终被插入的位置)的多个偏移位置写入某个长度的值,比如页头的记录数,槽数,页尾槽数据,页中的记录值等等,这些本是一些物理操作,而innodb为了节约日志量及其它一些原因,设计为逻辑处理的方式,那就是它会在一个页面的基础上,把一条记录插入,那么在日志记录中记录的内容为表空间号、页面号、记录的各个列的值等等,在内部转换为上面的物理操作。
但这里的一个问题是,如果那个页面本身是错误的,这种错误有可能是因为写断裂(1个页面为16K,分多次写入,后面的有可能没有写成功,导致这个页面不完整)引起的,那么这个逻辑操作就没办法完成了,因为它的前提是这个页面还是正确的,完整的,因为如果这个页面不正确的话,这个页面里的数据是无效的,有可能产生各种不可预料的问题。
那么正是因为这个问题,所以必须要首先保证这个页面是正确的,方法就是两次写,它的思想最终是一种备份思想,也就是一种镜像。
innodb两次写的过程:
可以将两次写看作是在Innodb表空间内部分配的一个短期的日志文件,这一日志文件包含100个数据页。Innodb在写出缓冲区中的数据页时采用的是一次写多个页的方式,这样多个页就可以先顺序写入到两次写缓冲区并调用fsync()保证这些数据被写出到磁盘,然后数据页才被定出到它们实际的存储位置并再次调用fsync()。故障恢复时Innodb检查doublewrite缓冲区与数据页原存储位置的内容,若数据页在两次写缓冲区中处于不一致状态将被简单的丢弃,若在原存储位置中不一致则从两次写缓冲区中还原。